
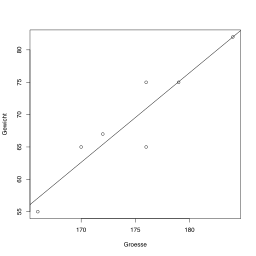
Linear regression is a statistical method used to model the relationship between a dependent variable and one or more independent variables.
It assumes a linear relationship between the variables and aims to find the best-fitting line that minimizes the sum of squared errors.
Linear regression can help in predicting housing prices based on factors such as location, size, number of bedrooms, and other relevant features.
Linear regression is used in finance to forecast stock prices, interest rates, or exchange rates based on historical data and other economic indicators.
In education, linear regression can be applied to predict student performance based on factors such as attendance, study hours, and previous academic scores.
Logistic regression is used for binary classification problems where the dependent variable is categorical and has only two possible outcomes.
It models the probability that an observation belongs to a particular class using a logistic function.
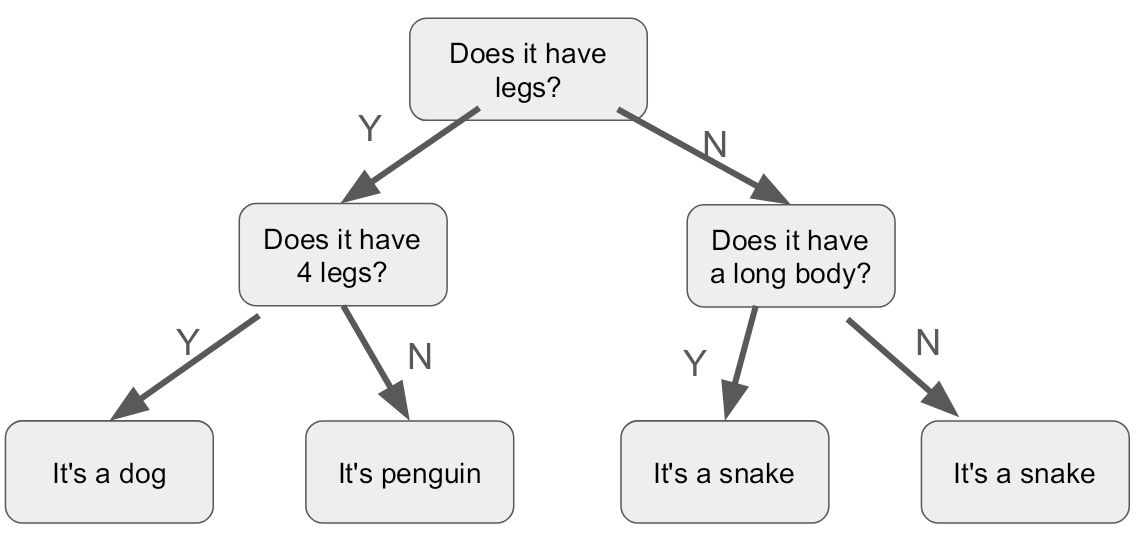
Decision tree induction involves creating a tree-like structure from a dataset, where each internal node represents a decision based on an attribute, and each leaf node represents a class label or outcome.
It involves selecting the best attributes to split the dataset at each node and determining the decision rules that lead to the most accurate predictions.
The structure is formed by dividing the original dataset, forming the root node of the tree, into subsets, which become the child nodes. This process can then be repeated as necessary.
It's a popular algorithm for classification and regression tasks, especially for those new to machine learning as it is simple to understand.
Predicting customer churn in telecommunications industry based on factors such as call duration, frequency of calls, and customer demographics.
Identifying fraudulent transactions in banking by analyzing transactional data including transaction amount, location, and time.
Random forests are an ensemble learning method that combines multiple decision trees to improve predictive performance and reduce overfitting.
Each tree in the forest is trained on a random subset of the data, and predictions are made by averaging the predictions of individual trees.
Gradient boosting machines are another ensemble learning technique that builds a sequence of weak learners (typically decision trees) in a sequential manner.
Each new learner focuses on the errors made by the previous ones, leading to improved predictive accuracy.
Support vector machines are a powerful supervised learning algorithm used for classification and regression tasks.
They find the hyperplane that best separates the classes in the feature space, maximizing the margin between classes.
Neural networks are a class of deep learning models inspired by the structure and function of the human brain.
They consist of interconnected layers of neurons that learn complex patterns and relationships in the data through a process called backpropagation.
Time series analysis is used for predicting future values based on past observations collected at regular time intervals.
Techniques such as autoregressive integrated moving average (ARIMA), seasonal decomposition, and exponential smoothing are commonly used for time series forecasting.
K-nearest neighbors is a simple yet effective algorithm used for classification and regression tasks.
It predicts the class or value of a new data point based on the majority class or average value of its k nearest neighbors in the feature space.