
Sound representation refers to the methods and techniques used to describe and store audio or sound information in a format that can be processed, transmitted, or stored by electronic devices and systems.
Sound in the real world is analog, represented as continuous variations in air pressure (sound waves). To work with sound in digital devices, it must be converted to a digital format.
When audio is converted from analog to digital, it is represented is a series of numerical values, typically sampled at regular intervals.
These samples capture the amplitude (loudness) of the sound at each point in time.
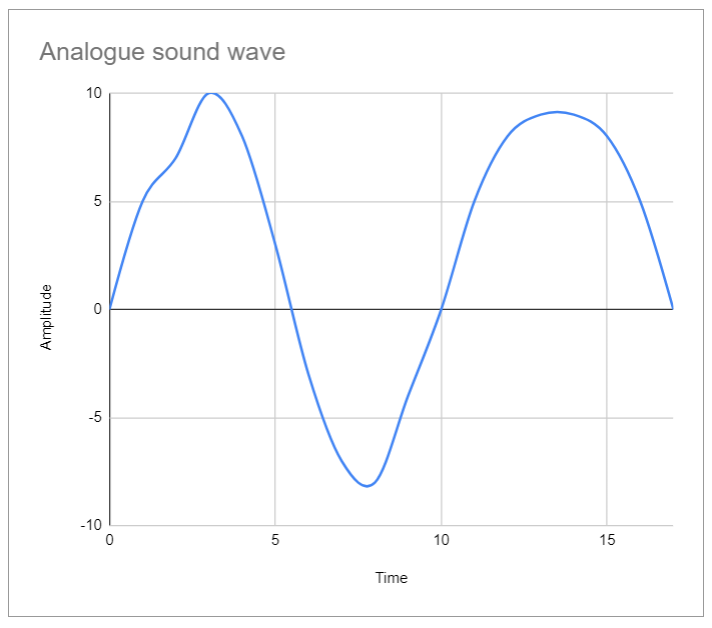
Here is an analog sound wave, drawn against a amplitude vs time graph.
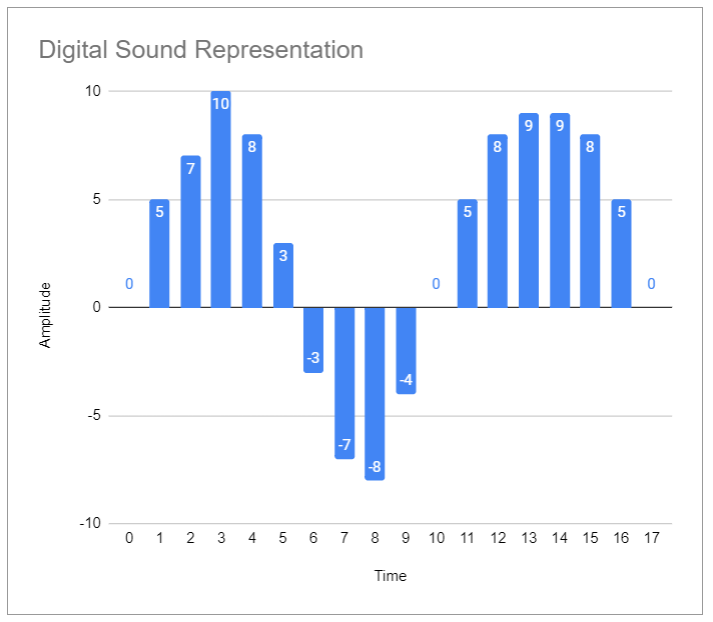
Here are the amplitude samples, sampled at a rate of 1000hz (1000 times per second)
0, 5, 7, 10, 8, 3, -3, -7, -8, -4, 0, 5, 8, 9, 9, 8, 5, 0
What is sound representation?
The sampling rate, often referred to as the sampling frequency, is the number of audio samples taken per second during the analog-to-digital conversion process.
It is measured in Hertz (Hz), which indicates the number of samples per second.
A higher sample rate can result in better audio quality, especially for high-frequency content. It allows for the accurate representation of fast-changing audio signals.
Sampling Resolution, often referred to as bit depth, determines the number of bits used to represent the amplitude of each audio sample.
It is measured in bits (e.g., 16-bit, 24-bit, etc.).
Higher bit depths provide better audio quality because they can represent a wider dynamic range, resulting in less quantization noise (noise introduced due to limited bit depth).
Lossy sound compression reduces audio file sizes by selectively discarding data, trading off some audio quality, and applying perceptual coding. Popular formats like MP3 and AAC use these techniques, making them suitable for music streaming and storage.
However, compression introduces artifacts, impacting audio quality. Users can adjust bit rates to balance quality and file size
There are a number of different lossy sound compression techniques, including:
Lossy compression algorithms are designed based on psychoacoustic principles, which study how humans perceive sound. This knowledge is used to identify parts of the audio that are less audible or masked by louder sounds.
Sounds at certain frequencies can mask or hide sounds at nearby frequencies. Lossy compression can quantize or remove data in these masked areas since the human ear is less sensitive to them.
Just as sounds at certain frequencies can mask others, loud sounds can temporarily mask quieter sounds that occur shortly before or after them. Lossy compression can take advantage of this phenomenon by quantizing or discarding data in these time intervals.