
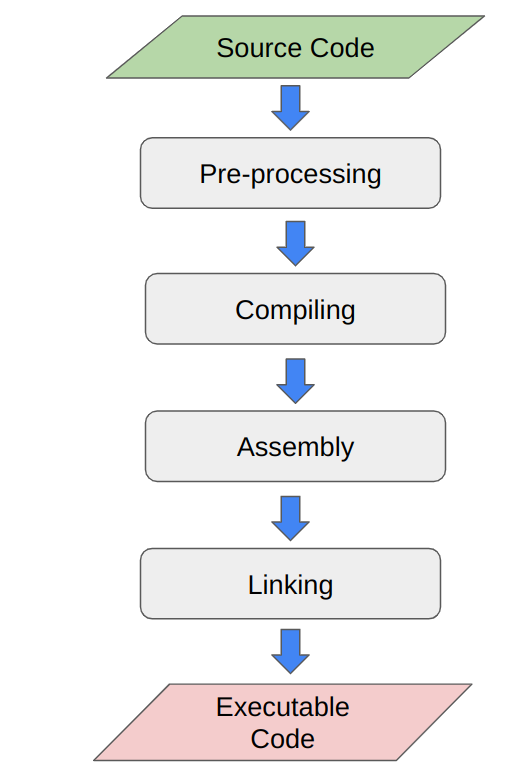
The process of converting source code into executable code is generally referred to as the "compilation process" or "build process".
This process includes several distinct stages:
Together they transform human-readable source code into machine-executable binaries.
Each stage plays a crucial role in ensuring that the code is syntactically correct, semantically meaningful, and optimized for execution on a specific hardware architecture.
The preprocessing stage handles directives (like #include, #define, etc.) in the source code. These directives are specific instructions to the preprocessor, which is responsible for preparing the code before it goes to the compiler.
File Inclusion: Replaces #include directives with the content of the included files.
Macro Expansion: Replaces macros defined by #define with their corresponding values.
Conditional Compilation: Handles conditional compilation directives like #ifdef, #ifndef, etc., to include or exclude parts of the code.
Output: The preprocessor produces a single expanded source code file with all the directives resolved, ready for the next stage.
What is the first step in the software development process?
The compiler takes the preprocessed code and translates it into assembly code, which is a low-level, human-readable form of machine instructions specific to the target CPU architecture.
Syntax Checking: The compiler checks the source code for syntax errors.
Semantic Analysis: The compiler ensures that the code makes logical sense (e.g., variables are declared before use).
Optimization: The compiler may perform optimizations to improve the performance or reduce the size of the generated code.
Output: The compiler outputs an assembly code file (.s or .asm), which is a step closer to machine code but still human-readable.
What is a compiler?
The assembler converts the assembly code produced by the compiler into machine code, which consists of binary instructions specific to the target CPU architecture.
Instruction Translation: Each assembly instruction is translated into a corresponding machine code instruction.
Symbol Resolution: The assembler resolves labels and other symbolic references to memory addresses.
Output: The assembler outputs an object file (.o or .obj), which contains machine code but is not yet a complete executable because it may contain unresolved references to external libraries or other parts of the program.
What is the main purpose of an assembler?
The linker combines one or more object files and resolves any remaining references to create a single executable file that can be run by the operating system.
Symbol Resolution: The linker resolves symbols that were not resolved during assembly, such as function calls between different object files or calls to external libraries.
Address Assignment: The linker assigns final memory addresses to each piece of code and data in the executable.
Library Linking: The linker includes code from static libraries or prepares the executable to link dynamically to shared libraries at runtime.
Output: The linker produces an executable file (.exe, .out, etc.), which contains all the necessary code and data to be executed by the operating system.
What is the role of a linker?
The compilation process is divided into separate steps—preprocessing, compiling, assembly, and linking—to make the conversion from source code to executable code more efficient, manageable, and flexible.
Specialization: Each step focuses on a specific task (e.g., preprocessing handles macros, compiling checks syntax), optimizing the overall process.
Efficiency: Only modified parts of the code need to be recompiled, speeding up builds.
Modularity: Intermediate files allow for easier debugging and reuse across projects.
Platform Independence: The process can target different hardware platforms by altering only specific stages.
Error Detection: Problems are caught at different stages, making it easier to identify and fix issues.