A relational database is a type of database that stores data in a structured format using rows and columns, often organized into tables.
These databases rely on the relational model proposed by Edgar F. Codd in 1970, where the data is logically stored in relations (tables) and accessed using a standardized query language, most commonly SQL (Structured Query Language).
A organizes data into tables that can be related to each other.
Tables (Relations)
A table consists of rows (records) and columns (attributes).
Each table should have a unique name within the database.
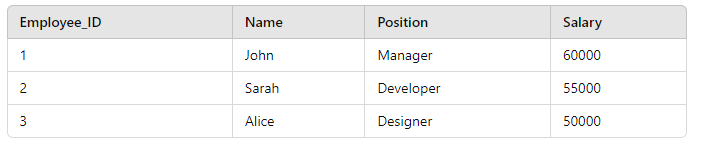
Example Table
In a relational database, a is often represented as a table.
Rows (Tuples)
Each row in a table represents a unique record.
For example, in the employee table, each row represents a single employee.
Each in a table corresponds to a unique record.
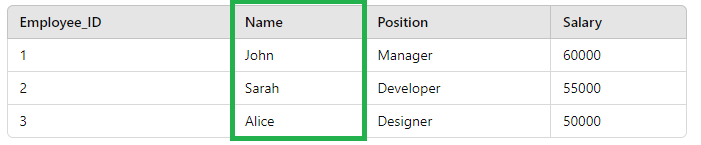
Columns (Attributes)
Columns represent data categories. Each column in a table holds values of a specific type (e.g., integers, strings, dates).
Columns in a relational database table represent specific of the data.
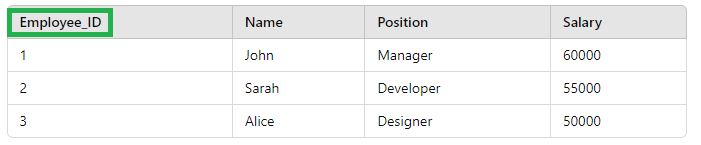
Primary Key
A primary key is a column (or a set of columns) that uniquely identifies each row in a table. No two rows can have the same primary key value.
Example: In the employee table, "Employee_ID" could be the primary key, as each employee has a unique ID.
The key used to identify a unique record in a table is called the .
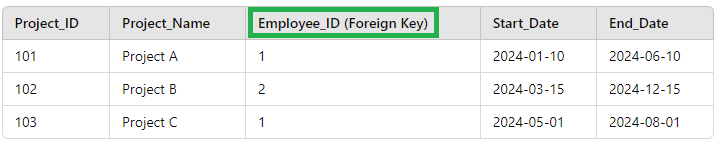
Foreign Key
A foreign key is a column (or a set of columns) in one table that refers to the primary key of another table. It establishes a relationship between the two tables.
Projects Table Example
In this case, the Employee_ID in the Projects table will act as a foreign key that references the Employee_ID in the Employees table.
A is a field in one table that links to the primary key of another table.
Relationships
One-to-One
One row in a table is related to one row in another table.
One-to-Many
One row in a table is related to multiple rows in another table.
Many-to-Many
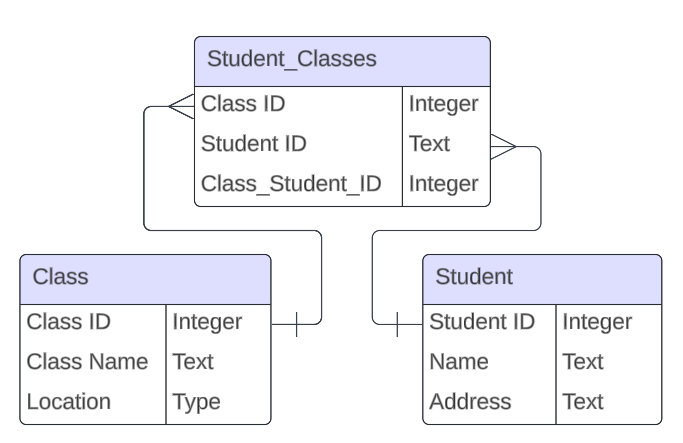
Multiple rows in one table are related to multiple rows in another table, usually implemented with a junction table.
What type of relationship is represented by a one-to-many relationship?
Junction Tables
A junction table (also known as a bridge table or associative entity) is a database table used to implement many-to-many relationships between two other tables.
Since relational databases don't directly support many-to-many relationships, the junction table helps by storing pairs of foreign keys referencing the primary keys of the related tables.
In a junction table, each row typically contains at least two that point to the primary keys of the related tables.
Normalization
The process of organizing data to reduce redundancy and dependency by splitting large tables into smaller, related tables.
The aim is to eliminate data anomalies (like insertion, update, and deletion anomalies) and make the database more efficient.
The process is normally split into First, Second and Third normal form (1NF, 2NF, 3NF).
Data is the process of organizing data to reduce redundancy and improve integrity.
Advantages of Relational Databases
Data Integrity
Constraints like primary keys, foreign keys, and unique constraints ensure the consistency and integrity of the data.
Flexibility
Relational databases are flexible and can handle a wide variety of data types.
Scalability
They can efficiently manage large volumes of data, especially when the schema is well-designed.
Standardization
SQL is a standardized language, making it easier to transfer knowledge and interact with different database systems (e.g., MySQL, PostgreSQL, Oracle, SQL Server).
ACID Properties
Relational databases follow the ACID properties (Atomicity, Consistency, Isolation, Durability) to ensure reliable transactions.
Disadvantages of Relational Databases
Complexity in Handling Large Amounts of Unstructured Data
Relational databases are not designed for handling unstructured data (e.g., large text files, multimedia content), which is better suited for NoSQL databases.
Scalability in Distributed Environments
While relational databases can handle large data sets, they may face challenges in highly distributed, cloud-based, or big data environments due to their reliance on a central server or clustered setup.
Performance Issues with Large Scale Operations
Complex queries on large data sets, especially those involving multiple joins, can lead to performance bottlenecks.